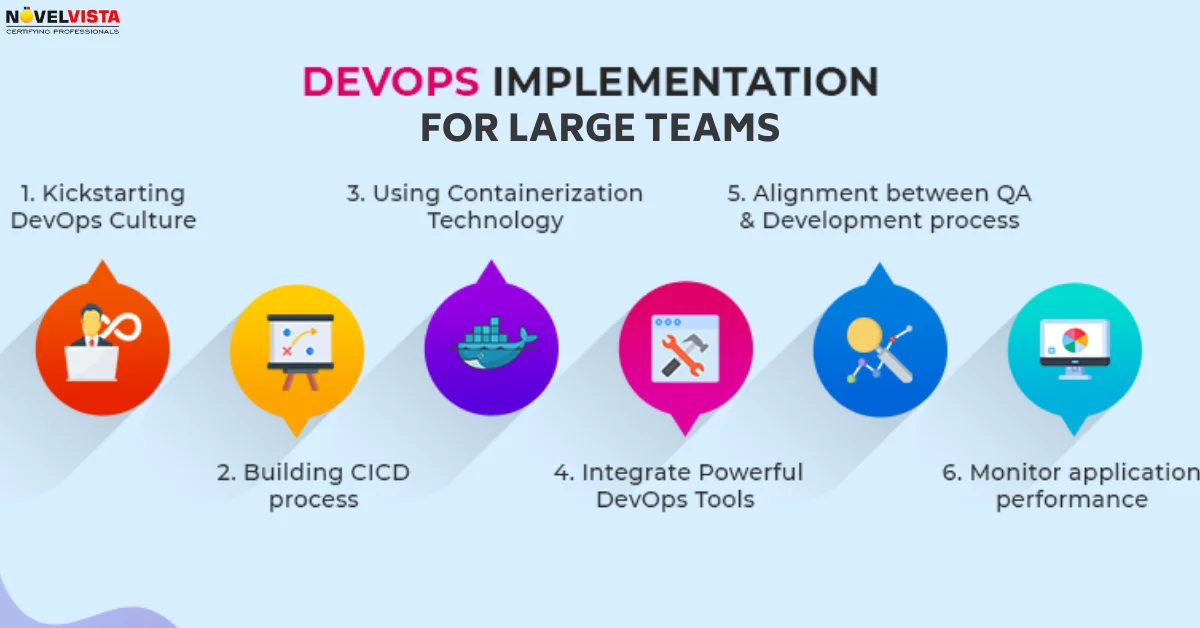
Site Reliability Engineering (SRE)is a discipline that combines software engineering and operations to
build and maintain reliable and scalable systems.
SREsfocus on ensuring the
reliability, availability, and performance of systems, while also managing incidents and minimizing downtime.
SREs use a
data-driven approach, leveraging automation and monitoring toolsto drive efficiency and improve system reliability.
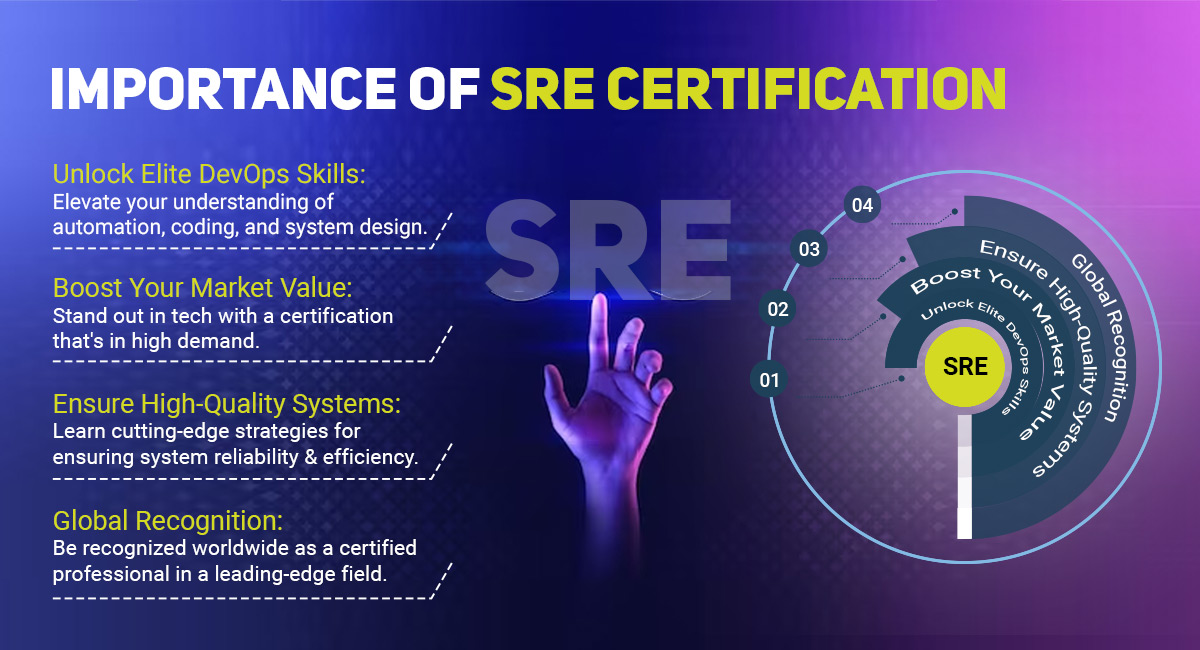
SRE Courses not only validate an individual's expertise in site reliability engineering but also demonstrate their commitment to continuous learning and improvement.
SRE Certification serves as a testament to an individual'sability to manage incidents effectively, implement best practices, and drive operational excellence.Organizations recognize the importance of SRE Certification and often prioritize certified professionals when hiring for critical roles.
To excel in incident management and earnSRE Certification, aspiring professionals must understand and practice key lessons.
First and foremost, it is crucial to establish clear incident management processes and workflows.
This involves defining roles and responsibilities, establishing communication channels, and implementing incident response playbooks.
By having well-defined processes in place, SREs can respond to incidents promptly and effectively, minimizing the impact on system availability.
Secondly,SREs must prioritize incident detection and monitoring. Proactive monitoring allows for early detection of potential issues, enabling SREs to address them before they escalate into major incidents.Implementing robust monitoring tools and establishing effective alerting mechanisms ensure that SREs are always aware of system performance and can take timely action.
Lastly,continuous improvement is a key lesson in incident management. SREs should conduct thorough post-incident reviews to identify root causes and develop preventive measures.
By learning from incidents and implementing corrective actions, SREs can enhance system reliability and prevent future incidents.

Implementing best practices in incident management is crucial for aspiring SREs looking to achieve certification.
Firstly,SREs should prioritize incident response time. The ability to respond promptly and efficiently to incidents is essential to minimizing downtime and ensuring system reliability.
SREs should establish clear escalation paths and implement effective incident response playbooks to streamline the response process.
Secondly,effective communication is key to incident management. SREs should establish clear communication channels, both within the team and with stakeholders, to ensure that everyone is informed about the status of incidents.
Regular updates and transparent communication help manage expectations and maintain trust.
Furthermore, automation plays a vital role in incident management for SREs. Automating repetitive tasks and implementing self-healing systems can significantly reduce incident resolution time and improve overall system reliability.
SREs should leverage automation tools to streamline incident response and focus on higher-value tasks.
Case studies are an invaluable learning tool for aspiring SREs. By analyzing real-world examples of incident management, we can gain key insights into best practices and understand how critical thinking and expertise can be applied to handle complex scenarios.

To showcase incident response in action, let's explore two illuminating case studies from industry-leading technology companies.
These examples demonstrate the techniques and skill sets SRE teams implement when managing high-impact incidents under intense pressure, highlighting why effective incident management capabilities are indispensable for any organization prioritizing reliability and uptime.
By learning from the experiences and solutions outlined in these case studies, we can enhance our preparedness to manage incidents in dynamic, real-world environments
A few years ago, a widespread outage impacted atop e-commerceplatform during peak sales season, causing transaction processing issues across payment gateways.
As revenue hemorrhaged by the minute, the on-call SRE engineer received alerts about payment failures and immediately assembled an incident response team.
They quickly discovered the root cause—a fault in a recently deployed code update that destabilized third-party payment integrations.
Implementing the company's incident response playbook, the SREs rolled back the problematic code release and reverted impacted systems to a last-known-good state while the development team prepared a patch.
Proactive customer communications set proper expectations about temporary checkout issues.
With their swift and coordinated actions, the SRE team resolved the critical incident in less than 15 minutes, saving millions in potential lost sales.
A majorsocial media platform faceda complex issue when widespread DDoS attacks overwhelmed DNS servers.
As the site experienced massive outages and cascading failures, SREs rapidly executed the runbook for DDoS events.
Thesecurity SREsadded extra protective controls, scrubbed malicious traffic at various infrastructure layers, and expanded capacity by activating regional resiliency zones.
Concurrently, the core SRE teams traced and patched vulnerabilities being targeted, while cloud engineers routed and loaded balanced traffic to ensure availability across geographies.
With systematic triage and real-time coordination, the cross-functional SRE crews successfully neutralized the ongoing DDoS assault and gradually restored service globally over several hours.
Despite the scale of the incident, proactive preparation and world-class SRE practices prevented irreparable business impact.
SRE Certification is a valuable credential for professionals in the field of site reliability engineering.
By understanding the key lessons in incident management and implementing best practices, aspiring SREs can enhance their skills and increase their chances of achieving certification.
Incident management plays a vital role in ensuring system reliability and minimizing downtime, making it a critical skill for SREs to master.
By continuously learning and improving, aspiring SREs can excel in their careers and contribute to the success of organizations in today's technology-driven world.
Are you ready to take your career in site reliability engineering to the next level?
Start your journey towards the NV
Site Reliability Engineering courseand unlock new opportunities for professional growth and development!

Confused about our certifications?
Let Our Advisor Guide You